# Distributed System
# Concepts
clock
- logical clock — a kind of monotonically growing counter
- physical clock, aka wall clocks — bound to physical time, accessible through process-local means
distributed algorithm goals
- coordination — a process that supervises the actions and behavior of several workers
- cooperation — multiple participants relying on one another for finishing their tasks
- dissemination — processes cooperating in spreading the information to all interested parties quickly and reliably
- consensus — achieving agreement among multiple processes
- two generals' problem — always one
ACKaway from reaching a consensus, wikipedia (opens new window) - FLP impossibility — if we do not consider an upper time bound for the process to complete the algorithm steps, process failures can’t be reliably detected, and there’s no deterministic algorithm to reach a consensus
- synchrony assumption — there is an upper time bound in time difference between the two process-local time sources
- two generals' problem — always one
links
- fair-loss link
- fair loss — if both sender and recipient are correct and the sender keeps retransmitting the message infinitely many times, it will eventually be delivered
- finite duplication — sent messages will not be delivered infinitely many times
- no creation — a link will not create messages never sent
- stubborn link — sender keeps retransmitting until acknowledgement
- perfect link
- reliable delivery — every message sent once by the correct process A to the correct process B, will eventually be delivered
- no duplication
- no creation
- fair-loss link
fallacies of distributed systems
- latency
- processing — not instantaneous
- remote execution latency and other problems
- clock and time — time drift
- state consistency
- network partition and partial failures
- network partition — two or more servers cannot communicate with each other
- partial failures — a part of a system is unavailable or functioning incorrectly
- cascading failures — a failed node increase load on other nodes; recovery exhausting network resources; corruption that can propagate through standard delivery mechanisms
- alleviate — planning and coordinating execution (load balance), circuit breakers, jittered exponential backoff, checksumming and validation (for bit rots)
- latency
# Failure Detection
failure models
- crash fault
- crash-stop — processes crash and stay in the state; the model means that the algorithm does not rely on recovery for correctness or liveness; nothing prevents processes from recovering, catching up with the system state, and participating in the next instance of the algorithm
- crash-recovery — recoverable, durable state and continued execution attempts
- omission fault — the algorithm that was supposed to execute certain steps either skips them or the results of this execution are not visible
- example — the process skips some of the algorithm steps, or is not able to execute them, or this execution is not visible to other participants, or it cannot send or receive messages to and from other participants
- arbitrary fault or Byzantine fault — out of control and supplying incorrect values
- origin — spies in the Byzantine army deliver false messages deliberately
- example — a process in a consensus algorithm decides on a value that no other participant has ever proposed; can happen due to bugs in software, or due to processes running different versions
- crash fault
testing and failure handle
- testing — create partitions, simulate bit rot, increase latencies, diverge clocks, and magnify processing speed differences
- handle
- mask failures — forming process groups and introducing redundancy into the algorithm
- more?
failure detection concepts
- failure detector — a local subsystem responsible for identifying failed or unreachable processes to exclude them from the algorithm and guarantee liveness while preserving safety
- liveness — guarantees that a specific intended event must occur. For example, if one of the processes has failed, a failure detector must detect that failure
- safety — unintended events will not occur. For example, if a failure detector has marked a process as dead, this process had to be, in fact, dead
- failure-detection algorithm essential properties
- completeness — every non-faulty member should eventually notice the process failure, and the algorithm should be able to make progress and eventually reach its final result
- tradeoff — efficiency - accuracy
- failure detector — a local subsystem responsible for identifying failed or unreachable processes to exclude them from the algorithm and guarantee liveness while preserving safety
failure detection algorithms
- failure detection: heartbeats and pings
- deadline failure detector — uses heartbeats and reports a process failure if it has failed to register within a fixed time interval
- problem — ping frequency and timeout, and interprocess connectivity
- timeout-free failure detector: heartbeat with counter — send heartbeats with their travel path, tbd (opens new window)
- outsourced heartbeats — if no response for a ping, demand other randomly selected nodes to ping and forward ACK back
- phi-accrual (φ-accrual) failure detector — a probability instead of a binary state
- suspicion level φ — computed by comparing the actual heartbeat arrival time, with the approximated arrival time sampled by a sliding window of arrival times of the most recent heartbeats
- dynamic — dynamically adapts to changing network conditions by adjusting the scale on which the node can be marked as a suspect
- deadline failure detector — uses heartbeats and reports a process failure if it has failed to register within a fixed time interval
- other failure detection
- gossip-style failure detection — each member maintains a list of other members, their heartbeat counters and last updated timestamps. Periodically, each member increments its heartbeat counter and distributes its list to a random neighbor. Nodes also periodically check the list of states and heartbeat counters. If any node did not update its counter for long enough, it is considered failed (or unreachable).
- FUSE (failure notification service) — processes divided into groups, processes within one group periodically ping others and in case of ping failure itself will stop respond to ping; for reliable and cheap failure propagation
- failure detection: heartbeats and pings
# Leader Election
election algorithms
- properties
- liveness — most of the time there will be a leader, and the election will eventually complete
- safety — at most one leader at a time, and completely eliminate the possibility of a split brain situation
- ideal — in practice, not met by many leader election algorithms
- split brain — when two or more leaders serving the same purpose are elected but unaware of each other
- possible split brain solution — cluster-wide majority of votes requirement; third party coordinator
- difference between distributed locks — other processes do not need to know who holds the lock, but not so for who is the leader
- determine leader status for reelection — failure detection algorithms
- properties
bully algorithm, monarchial leader election — each process preassigned a unique rank, the highest one wins election
- steps — the process send election message to the higher ranked, notify the highest that responded or itself if no higher is up, then the highest notify all lower-ranked processes about the new leader
- drawback
- prone to split brain in the presence of network partitions
- hot spots
- optimization variants
- next-in-line failover — when one of the processes detects a leader failure, it will send a message to the highest-ranked alternative from the failover list provided by the failed leader one by one; if one is able to ACK, it becomes a new leader and broadcasts the leadership
- candidate/ordinary optimization — spilt nodes into two subsets, candidate and ordinary, the ordinary node send election message to candidate nodes, and broadcasts the new leader which is the highest ranked among ACKs
- mitigate multiple simultaneous elections — adjust tiebreaker variable δ, a process-specific delay before initiate the election
invitation algorithm — allow multiple leaders by definition. Each process starts as a leader of a new group, inviting other leaders to join, when non-leader nodes are invited, respond with own leaders. Leaders broadcasts the new leader to its own group when joining another group, effectively merge two groups
- new leader when merging — choose the one in the larger group, keep the number of messages required to merge groups to a minimum
ring algorithm — all nodes in the system form a ring. A node starts election by forwarding live node set to its successor, if unreachable, successor's successor and so on until reachable. Itself appended to the live node set before forwarding. When the message comes back to the initial node, the highest-ranked node from the live set is chosen as a leader
- see also — timeout-free failure detector
- variant — only keep the highest ranked in the live set
consensus algorithms
# Replication Consistency
CAP conjuncture — CP or AP for choice
- consistency — atomic or linearizable consistency
- availability — the ability of the system to serve a response for every request successfully
- by redundancy and replication, which bring sync and recovery problem
- partition tolerance
- CAP extension
- PACELC — in presence of P, choose between A and C; else (E), even if the system is running normally, choose between latency (L) and consistency (C)
- harvest and yield — relaxed A and C, shifts the focus of the trade-off from the absolute to the relative terms
- harvest — how complete (consistent) the query is
- yield — request success rate, number of successfully completed requests compared to the total number of attempted requests
consistency model
- strict consistency — ideal
- linearizable — effects of the write become visible to all readers exactly once at linearization point at some instant between its start and end
- linearizability versus serializability — the latter is a isolation level, not composable, not imply any kind of deterministic order, simply requires that some equivalent serial execution exists
- sequential consistency — happen-before for the same-origin writes; cross-origin writes can be arbitrary order, but observed in the same order by readers
- causal consistency — all processes have to see causally related operations in the same order; logically timestamped, or dependencies (causal before operations or values) tracked
- examples using logical clocks
- Reusable Infrastructure for Linearizability (RIFL), a linearizable RPC mechanism by guaranteeing that the RPC cannot be executed more than once
- messages — uniquely identified with the client ID and a client-local monotonically increasing sequence number
- client ID — use lease, unique identifiers that expire after some time, have to be renewed periodically
- retry — return a associated completion object to the client if already executed
- completion object — associated with a operation, persisted along with the actual data records, removed when no more retry promised or crash detected (by lease expiration) on the client
- vector clock, detect causal conflicts — used by Dynamo; processes maintain vectors of logical clocks, with one clock per process; each clock starts at the initial value, is incremented upon a new event, and maximized upon receiving clock vectors from other processes (which is also an event)
- Lamport timestamp — a single value instead of a vector, vector clock is its improvement
- solve conflicts
- last-write-wins rule
- ask users — store causal history, add garbage collection, and ask the user to reconcile divergent histories
- Reusable Infrastructure for Linearizability (RIFL), a linearizable RPC mechanism by guaranteeing that the RPC cannot be executed more than once
session models, aka. client-centric consistency models, can be combined with each other
- read-own-writes consistency model — every write issued by the client is visible to it
- monotonic reads model — values read by the client should be at least as recent as last read ones
- monotonic writes model — effects by a client have to become visible in the same order to all other processes; otherwise, old data can be “resurrected”
- writes-follow-reads, aka. session causality — writes are ordered after writes that were observed by previous read operations
- example
- Pipelined RAM (PRAM) consistency, aka. FIFO consistency — monotonic reads, monotonic writes, and read-own-writes combined; unlike under sequential consistency, writes from different processes can be observed in different order
tunable consistency — when performing a write, the coordinator should submit it to N nodes, but can wait for only W nodes before it proceeds (or W - 1 in case the coordinator is also a replica). Similarly, when performing a read, the coordinator has to collect at least R responses
- replication factor N
- write consistency level W
- read consistency level R
- trade off — increase W, R increases latencies and require more node availability; decreasing them improves system availability while sacrificing consistency
- example
- consistent write-heavy systems — may sometimes pick W = 1 and R = N; W = N and R = 1 achieves the same
quorum
- definitions
- definition in the context of tunable consistency — a consistency level that consists of ⌊N/2⌋ + 1 nodes
- other definitions — the minimum number of votes required, usually satisfying some constraint like R + W > N
- constraints
- R + W > N — the system can guarantee returning the most recent written value
- W > N/2 — cannot write concurrently on the same data item
- does not guarantee monotonicity alone — in cases of incomplete writes, use blocking read-repair
- witness replica — witness replicas merely store the record indicating the fact that the write operation occurred, for improving storage costs, used in Cassandra
- motivation — replication with copy replicas only is storage costly
- upgrade — in cases of write timeouts or copy replica failures, witness replicas can be upgraded to copy replicas
- requirement for availability — n copy and m witness replicas has same availability guarantees as n + m copies, if W and R above majority and at least one replica is a copy replica in a quorum
- sloppy quorum — in case of replica failures, write operations can use additional healthy nodes from the node list for hinted handoff (see Anti-Entropy)
- definitions
eventual consistency
- BASE
- basically available
- soft state
- eventual consistency — if there are no additional updates performed against the data item, eventually all accesses return the latest written value
- strong eventual consistency — updates are allowed to propagate to servers late or out of order, but when all updates finally propagate to target nodes, conflicts between them can be resolved and they can be merged to produce the same valid state
- example: Conflict-Free Replicated Data Types (CRDTs), used in Redis Enterprise (opens new window) — specialized data structures that preclude the existence of conflict and allow operations on these data types to be applied in any order without changing the result
- example: collaborated editing (opens new window)
- Commutative Replicated Data Types (CmRDTs) — tbd
- unordered grow-only set (G-Set) — to reconstruct the current state of the set, all elements contained in the removal set are subtracted from the addition set, tbd
- example: Conflict-Free Replicated Data Types (CRDTs), used in Redis Enterprise (opens new window) — specialized data structures that preclude the existence of conflict and allow operations on these data types to be applied in any order without changing the result
- BASE
other consistency
- convergent consistency — see gossip
- external consistency — see Spanner
# Dissemination
- dissemination
- usage example — quick and reliable propagation may be less applicable to data records and more important for the cluster-wide metadata
- ways
- broadcast — see Consensus
- anti-entropy — periodic peer-to-peer information exchange
- gossip — message recipients become broadcasters and help to spread the information quicker and more reliably
# Anti-Entropy
anti-entropy — compares and reconciles missing or conflicting records; used to bring the nodes back up-to-date in case the primary delivery mechanism has failed
- foreground anti-entropy — piggyback read or write requests: hinted handoff, read repairs, etc.
- background anti-entropy — auxiliary structures such as Merkle trees and update logs to identify divergence
- Merkle trees — a compact hashed representation of the local data, building a tree of hashes; calculated recursively from the bottom to the top, a change in data triggers recomputation of the entire subtree; trade-off between the size of a tree and its precision
- bitmap version vectors — resolve data conflicts based on recency: each node keeps a per-peer log of operations that have occurred locally or were replicated. During anti-entropy, logs are compared, and missing data is replicated to the target node; tbd
read repair — repair when reading: replicas send different responses, the coordinator sends missing updates to the replicas where they’re missing
- asynchronous read repair
- blocking read repair — ensures read monotonicity for quorum reads
- no need to block every request — because of the read monotonicity of blocking repairs, we can also expect subsequent requests to return the same consistent results, as long as there was no write operation that has completed in the interim
- example: Cassandra — use specialized iterators with merge listeners, which reconstruct differences between the merged result and individual inputs. Its output is then used by the coordinator to notify replicas about the missing data.
digest read — the coordinator compare the digest of replicas before issue full reads: can issue only one full read if replicas in sync; has to issue full reads to any replicas that responded with different digests and reconcile
hinted handoff, a write-side repair mechanism — if the target node fails to acknowledge the write, the write coordinator or one of the replicas stores a special record, called a hint, which is replayed to the target node as soon as it comes back up
- use — Cassandra, and sloppy quorum (see before) in Riak
# Gossip
Gossip — the reach of a broadcast and the reliability of anti-entropy
gossip model — modeled like rumors or epidemics
- SIR model (opens new window)
- infectious — a process that holds a record that has to be spread around
- susceptible — processes have not received the update yet
- removed (recovered) — processes not willing to propagate the new state after a period of active dissemination
- consistency model: convergent consistency — nodes have a higher probability to have the same view of the events that occurred further in the past
- SIR model (opens new window)
gossip parameters
- fanout
f— periodically selectfpeers at random and exchange currently “hot” information with them - message redundancy — the overhead incurred by repeated delivery
- latency — the amount of time the system requires to reach convergence (note that when all peers notified, gossip can still last)
- ways to interest loss point
- probabilistically — the probability of propagation stop is computed for each process on every step
- threshold — the number of received duplicates is counted, and propagation is stopped when this number is too high
- fanout
overlay network — a temporary fixed topology in a gossip system, middle ground for randomness and non-probabilistic
- fix nodes to spread — nodes can sample their peers and select the best contact points based on proximity (usually measured by the latency)
- island problem — separated groups of nodes
- tradeoff — randomness for robustness and redundancy, non-probabilistic for less redundancy and more optimal route
- fix nodes to spread — nodes can sample their peers and select the best contact points based on proximity (usually measured by the latency)
partial view
- problem with full view — maintaining a full view of the cluster can get expensive and impractical, especially if the churn is high
- churn — measure of the number of joining and leaving nodes in the system
- peer sampling service — maintains a partial view of the cluster, which is periodically refreshed using gossip
- problem with full view — maintaining a full view of the cluster can get expensive and impractical, especially if the churn is high
hybrid gossip — fixed topologies when the system is in a stable state, fall back to gossip for failover and system recovery
- push/lazy-push multicast trees (plumtrees)
- overlay under normal conditions — construct and maintain a spanning tree overlay of nodes from the peer sampling service, so each node can send full messages to just a small subset of peers
- lazy-push — for the rest of the nodes outside the overlay path, each node lazily forwards only the message ID for the recipient to query back if the ID not seen yet, effectively fall back to gossip in case of failure and can repair the overlay simultaneously
- hybrid partial view (HyParView) protocol — each node maintains a small active view and a larger passive view of the cluster, for overlay and active view backup respectively, tbd
- push/lazy-push multicast trees (plumtrees)
# Distributed Transactions
2PC, two phase commit — used in XA, transaction manager as the coordinator
- two phase
- prepare — the coordinator collects vote from the cohorts
- commit/abort — the coordinator makes decision and broadcasts it to cohorts, commit iff all cohorts voted positively
- recovery — to accommodate recovery from failure (automatic in most cases) the protocol's participants use logging of the protocol's states, during each step the coordinator and cohorts have to write the results of each operation to durable storage to be able to reconstruct the state
- coordinator failure
- cohorts block waiting — if vote collected but failed to broadcast decision, cohorts remain in an undecided state, until coordinator recover or restart anew with a backup
- failover alleviation — information about the decision can be replicated from the peers’ transaction logs or from the backup coordinator
- variant: Spanner — perform 2PC over Paxos groups per partition rather than individual nodes to improve protocol availability; within the Paxos group, 2PC contacts only the node that serves as a leader
- TrueTime — a high-precision wall-clock API that also exposes an uncertainty bound, allowing local operations to introduce artificial slowdowns to wait for the uncertainty bound to pass
- operations
- read-write transactions — require locks, pessimistic concurrency control, and presence of the leader replica
- read-only transactions — lock-free and can be executed at any replica
- snapshot reads
- multi-version — multiple timestamped versions of the record can be stored
- Paxos group leader — every write has to go through the leader, which holds a lock table that is used to implement concurrency control using the two-phase locking
- external consistency — transaction timestamps reflect serialization order, even in cases of distributed transactions
- tbd
- variant: Percolator
- snapshot isolation (SI) — zhihu (opens new window)
- timestamp oracle — a source of clusterwide-consistent monotonically increasing timestamps
- tbd
- two phase
3PC — adds an extra step, and timeouts on both sides, to solve blocking of 2PC
- three phases
- propose — the prepare phase in 2PC
- prepare — if vote passed, the coordinator sends a Prepare message, instructing participants to be prepared, and then participants ACK
- commit — cohorts notified by the coordinator to commit
- add timeout
- timeout for prepare — cohorts may abort the transaction after timeout for Prepare command, solving the blocking problem of 2PC
- timeout after prepared — commit even if no commit command from coordinator in phase 3
- problem: split brain — network partition at the 2nd phase, making some nodes prepared while others not
- three phases
Calvin — let replicas agree on the execution order, tbd
- sequencer — an entry point for transactions, the timeline is split into epochs so transactions batched
coordination avoidance — I-Confluent operations can be executed without additional coordination
- Invariant Confluence (I-Confluence) — a property that ensures two invariant-valid but diverged database states can be merged into a single valid, final state
- invariant — invariants in this case preserve consistency in ACID terms
- merge function — required for bringing diverged states back to convergence
- required properties for coordination avoidance
- global validity — required invariants are always satisfied, for both merged and divergent commit‐ ted database states, and transactions cannot observe invalid states
- availability — if all nodes holding states are reachable by the client, the transaction has to reach a decision
- convergence — nodes are able to reach the same states if no further transactions and indefinite network partitions
- coordination freedom — local transaction execution is independent from other nodes
- example
- Read-Atomic Multi Partition (RAMP) — 2PC but attempt to reduce the amount of coordination by using invariants to determine where coordination can be avoided, and only paying the full price if it’s absolutely necessary, tbd
- Invariant Confluence (I-Confluence) — a property that ensures two invariant-valid but diverged database states can be merged into a single valid, final state
事务补偿机制 — command design pattern with undo operation, the invoker sorts and executes all concerned commands in order; if no dependency, concurrent execution is possible; use undo to recover in case of any exceptions
# Consensus
consensus properties
- agreement — the decision value is the same for all correct processes
- validity — the decided value was proposed by one of the processes
- termination — all correct processes eventually reach the decision
broadcast — see dissemination
- best effort broadcast — fail silently, do not try to rebroadcast the message
- reliable broadcast
- native approach: flooding algorithm — if sender crash detected, other processes forward it to every other process it is aware of as a fallback mechanism; messages and out of order
- atomic broadcast — see below
atomic broadcast, aka. the total order multicast — guarantees both reliable delivery and total order
- properties
- atomicity — either all non-failed processes deliver the message, or none do
- order — all non-failed processes deliver the messages in the same order
- examples
- virtual synchrony — use group view as broadcast barrier, message delivery only when message receipt for all the group members, and use a single process (sequencer) for message order, rarely used
- group view — the presentation of current active nodes in a group
- ZAB, ZooKeeper atomic broadcast — tbd
- leader and follower — followers forward requests to the leader, the leader turn requests into proposals and broadcast to all followers
- zxid — 64 bit proposal ID, higher 32 bit for epoch, low order 32-bits for the counter
- epochs — logical clock; during any epoch, there can be only one leader
- protocol steps, executed by the prospective leader
- leader election — choose prospective leader, by any reasonable election algorithm (safety is guaranteed by the further algorithm steps)
- discovery — the prospective leader learns about the latest epoch known by every other process, and propose a new epoch greater than the latest back to the followers, who then respond with the latest zxid seen in the previous epoch and update own acceptedEpoch
- synchronization — the prospective leader sync with followers (according to collected zxid) for recovery and to ensure consistency, if a quorum (majority) successfully synced, the leader is established
- broadcast — active messaging starts, 2PC like: the leader receives client messages, establishes their order, and broadcasts them to the followers: it sends a new proposal, waits for a quorum of followers to respond with acknowledgments and, finally, commits it
- virtual synchrony — use group view as broadcast barrier, message delivery only when message receipt for all the group members, and use a single process (sequencer) for message order, rarely used
- properties
Raft — visualization (opens new window)
- roles
- candidate — attempt to collect a quorum of votes to become a leader
- leader — handle client requests and interacts with a replicated state machine, for a certain period called term, aka. epoch, which a logical clock
- follower — persist log entries and respond to requests from the leader and candidates, also forward requests to the leader
- components
- periodic heartbeat — the leader periodically sends heartbeats to all followers to maintain its term
- leader election — if no heartbeat from leader for some time (election timeout), a follow becomes a candidate, term increments and the candidate requests votes from other nodes, the request includes the new term and the newest log entry; each node can vote at most one candidate and the candidate becomes leader if a quorum (majority) collected, or the candidate becomes a follower if heartbeat with a term not smaller than current term from a new leader received; restart if not enough vote till timeout, term also incremented when next election started
- stale candidates not qualified — if the follower’s log information is more up-to-date (has a higher term ID, or a longer log entry sequence), the follow will vote to deny this candidate
- term maximized and leader step down — term maximized upon receiving a request of any type, term incremented when the node starts a election; leader becomes a follower if its term got updated
- log replication / broadcast — the leader can repeatedly append new values to the replicated log and broadcast them
- commit an entry — an entry is considered committed if a quorum of ACK, and then it is committed on the leader locally; commit decision also replicated to followers, committing an entry also commits all entries preceding it; unsuccessful commit see below
- order keeping — a follower (require reconciliation or) rejects a higher-numbered entry if the ID and term of the entry that immediately precedes it, sent by the leader, do not match the highest entry according to its own records
- failure scenarios
- competing candidates — jittered timeout
- follower failure — retry of the leader, can be batched
- unsuccessful commit — due to network or replica slowness, already committed messages can still be seen as in progress, can be worked around by retrying a client command until it is finally committed
- restore state when new leadership — by finding a common ground (the highest log entry on which both the leader and follower agree), and ordering followers to discard all (uncommitted) entries appended after this point, and then sends the most recent entries from its log
- difference with Paxos — most notably, Raft only allows servers with up-to-date logs to become leaders, whereas Paxos allows any server to be leader provided it then updates its log to ensure it is up-to-date (piggybacking)
- roles
Byzantine consensus
- cross-validate — have to verify other nodes’ behaviors by comparing returned results with the majority responses, so most Byzantine consensus algorithms require messages to complete an algorithm step, where N is the size of the quorum
- Practical Byzantine Fault Tolerance (PBFT) — tbd
# Paxos
Paxos
- participants
- proposers — receive client requests, create proposals and receive votes
- proposal IDs — proposer distinct, e.g. global ID generator, e.g. slotted timestamp, e.g. 1, 3, 5... for proposer 1 and 2, 4, 6... for proposer 2
- acceptors — vote to accept or reject proposals
- learners — replicas, storing the outcomes of the accepted proposals
- proposers — receive client requests, create proposals and receive votes
- colocate — a single process can simultaneously be a proposer, an acceptor, and a learner
- two phases
- propose
- prepare — proposers send a
Prepare(n)message with proposal IDnto acceptors, possible to retry with a higher ID if got ignored and timeout - promise — acceptor check if it promised to ignore, if not, reply with
Promise(n), promising to ignore ID lower thann, along with accepted ID and valuePromise(m, v)if already accepted, piggybacking the value
- prepare — proposers send a
- replication — after collecting a quorum of votes, the proposer can start the replication
- start commit — proposer commits the proposal by sending acceptors an
Accept!(n, v), wherevis from piggybackedPromise(m, v)wheremis the highest or a self-picked value if noPromise(m, n)received from piggybacking - accept — acceptor check if it promised to ignore, if not, reply with
Accept(n, v), also send it to all learners - commit success — if proposer/learner get majority of
Accept(n, v), they know consensus reached onv
- start commit — proposer commits the proposal by sending acceptors an
- propose
- failure scenarios
- two or more proposers competing and overwrite the quorum of each other — avoid hot spots and contention by jittered exponential backoff
- proposer fail after at least one accept — if the client is connected only to the original proposer, the client might not know about the result of the Paxos round execution since two cases:
- value piggybacked and consensus reached
- value not piggybacked and consensus on a new value reached
- if no overlap of acceptors between the quorum of another proposer
- or if the accepted acceptors fail
- participants
multi-Paxos — aka. replicated log, avoid repeating the propose phase using leader with lease
- leader — a distinguished proposer, allows reads from the active leader without collecting a quorum
- stale proposer problem in vanilla Paxos — reads implementation can be implemented by running a Paxos round that would collect any values from incomplete rounds, which has to be done because the known proposer is not guaranteed to hold the most recent data
- lease — address above problem: participants will not accept proposals from other leaders for the period of the lease; the leader periodically contacts the participants, notifying them that it is still alive, effectively prolonging its lease
- prerequisite — rely on the bounded clock synchrony between the participants
- difference with Raft — see before
fast Paxos — reduce the number of round-trips by one, tbd
- participants besides those in vanilla Paxos
- coordinator — the proposer that has collected a sufficient number of responses during the propose phase
- acceptor size — 3f + 1, where f is the number of processes allowed to fail
- quorum size — 2f + 1
- mode
- classic — as vanilla Paxos
- fast — if the coordinator is permitted to pick its own value during the replication phase, the coordinator can issue a special
Anymessage to acceptors, making acceptors accept values from any proposer
- prone to collisions — if two or more proposers attempt to use the fast step, the coordinator has to intervene and start recovery by initiating a new round
- participants besides those in vanilla Paxos
egalitarian Paxos, aka. EPaxos — benefits of both classic Paxos where leader established each round, and multi-Paxos where leader can be hot spot but high throughput
- dependency conflict checking, tbd
flexible Paxos — use R + W > N as quorum, allows trading availability for latency
- example — if we have five acceptors, as long as we require collecting votes from four of them to win the election round, we can allow the leader to wait for responses from two nodes during the replication stage
- variants — vertical Paxos
generalized solution — tbd, A Generalised Solution to Distributed Consensus (opens new window)
variants which are read-modify-write registers instead of write-once registers
# Other
# Message Queues
message queue
- purpose
- decoupling
- pipelining — requests in different stages are processed by independent parts of the system. The subsystem responsible for receiving messages doesn’t have to block until the previous message is fully processed.
- absorbing short-time bursts
- model
- point to point — JMS queues, like producer / consumer or load balance model, message can only be acknowledged once
- publish / subscribe — JMS topics, like events
- durable and non-durable subscriber — whether message persisted for unreachable subscribes
- 集群订阅 — publish / subscribe for clusters, PTP for nodes in clusters
- purpose
message queue posting and delivery
- message acknowledgement in
javax.jms.SessionAUTO_ACKNOWLEDGE— after the reception of message (when the session has successfully returned from a call toreceiveor when the message listener called to process the message successfully returns)CLIENT_ACKNOWLEDGE— afterjavax.jms.Message::acknowledgeDUPS_OK_ACKNOWLEDGE— batched, sends a client acknowledgment each time received a fixed number of messages, or when a fixed time interval has elapsed since the last acknowledgment was sent; the broker may redeliver the same message more than onceSESSION_TRANSACTED— deliver and consume messages in a local transaction
- 发送端的可靠性 — 发送端完成操作后一定能将消息成功发送到消息队列中
- implementation: 使用本地事务 — 利用本地事务来保证对本地消息表与业务数据表的操作满足事务特性:将消息表中的消息转移到消息队列中,若转移消息成功则删除消息表中的数据,否则继续重传
- 限制:有时发送消息和业务操作难以集成在一个本地事务 — resort to distributed transactions
- implementation: message middleware with message state
- send message
- producer send message with pending state to message middleware
- message middleware store the message and ACK
- producer do business logics
- producer send the result of business logics to the message middleware, also complete the message content if necessary
- message middleware change the message state accordingly: enable consuming for the message if success, delete the message otherwise
- the message middleware polls for message state periodically to see if the producer failed to update the message state
- send message
- implementation: 使用本地事务 — 利用本地事务来保证对本地消息表与业务数据表的操作满足事务特性:将消息表中的消息转移到消息队列中,若转移消息成功则删除消息表中的数据,否则继续重传
- 接收端的可靠性 — no duplicated consumption
- idempotent message consuming
- 保证消息具有唯一编号,并使用一张日志表来记录已经消费的消息编号
- ordered consumption — one queue/partition and one consumer
- message acknowledgement in
message queue availability and performance
- distribution in Kafka
- partition — one topic distributed in multiple partitions, one broker has one or more partitions
- leader / follower — read / write from the leader, with failure detection and reelection
- optimization
- producer
- asynchronous sending — do not wait ACK after message sent
- ProducerFlowControl — 消息堆积,井超过限制大小的情况下,ActiveMQ 就会让消息生产者进入等待状态或者在发送者端直接抛出
JMSException; 需要设置回执窗口,发送若干次后等待服务端进行回执
- consumer
- dispatch async — 推送消息后,不会等待消费者的响应信息,直到消费者处理完消息后,主动向服务端返回处理结果
- prefetch — 主动按照设置的规则推送给当前活动的消费者
- dead letter queue — transfer the message to dead letter queue when the redeliver count exceeds threshold
- transaction — messages redelivered to the same session upon rollback, or failure to commit
- producer
- other features
- message priority
- distribution in Kafka
Redis queue
- plain point to point queue —
RPOP,BRPOP - pub/sub queue —
XREAD - reliable queue —
LMOVEto pending list, andLREMthe pending list to ACK, can also monitor and re-push pending list items based on timeout - task queue —
LMOVEwith the same source and destination, e.g. a monitoring system that must check that a set of web sites are reachable, with the smallest delay possible, using a number of parallel workers - Kafka consumer group —
XREADGROUP - time series store —
XRANGE,XREVRANGE
- plain point to point queue —
delayed queue
- use cases — timed events, like notification push, auto canceling
- Redis ZSet polling
- add —
ZADD key timestamp task, also using consistent hashing to distribute on different keys for performance and scalability - polling —
ZRANGEBYSCORE key -inf +inf limit 0 1 WITHSCORES, one or more processes for one or more keys - async execution — for example, send to normal message queue
- add —
- RabbitMQ — TTL as delay, or directly use the community delayed message exchange plugin (opens new window)
- dead lettering — message posted to dead letter exchange to be redirected to dead letter queue when: message rejected using
basic.rejectorbasic.nackwithrequeuefalse; message TTL timed out; message queue length exceeded - TTL — TTL of a queue, expired timely; TTL of a message, expiration examined only for the message at queue head, use the community plugin above to support delay for each message
- dead lettering — message posted to dead letter exchange to be redirected to dead letter queue when: message rejected using
- time wheel — circular list, each node as message queues
- add — O(1), e.g. if the pointer points to 2 at the moment, add the task with 3s delay at 5
- hierarchical — like second hands, minute hands, hour hands on watches
- empty bucket optimization in Kafka — use
java.util.concurrent.DelayQueueto spin the time wheel
# Distributed Locks
unique index of a database — insert a record as lock acquiring, delete the record as lock releasing
- plain unique index in traditional relational database
- problems
- no lease or timeout
- can only be non-blocking
- not reentrant
- problems
SETNXandEXPIREin Redis- deprecated —
SETNXthenEXPIREnot atomic, useSETwith parameters instead, see redis.io (opens new window) for exampleSET key value [EX seconds|PX milliseconds|KEEPTTL] [NX|XX] [GET] - possible to
DELkey owned by other client — when the lock expired before a client can finish its operation- solution — use client ID or random string as the value to compare and
DELif redis.call("get",KEYS[1]) == ARGV[1] then return redis.call("del",KEYS[1]) else return 0 end
- solution — use client ID or random string as the value to compare and
- problem: lock lost — the underlying Redis instance failed before the very key is replicated
- distributed variant — RedLock, see below
- deprecated —
RedissonLockin redisson, a Redis Java client — lua scripts encapsulated, also reentrant
- plain unique index in traditional relational database
RedLock — use several independent Redis instances, see redis.io (opens new window)
- acquire lock on single instance —
SETwith parameters, see above - steps
- try to acquire lock from multiple Redis instances sequentially, with a smaller timeout compared to lock validity time (e.g. 5~50 ms vs 10s)
- retry — jittered backoff, waits a time which is comparably greater than the time needed to acquire the majority of locks
- multiplexing — the faster a client tries to acquire the lock in the majority of Redis instances, the smaller the window for a split brain condition (and the need for a retry), so ideally the client should try to send the
SETcommands to the N instances at the same time using multiplexing
- iff a quorum (majority) of locks acquired and the time spent acquiring the lock is less than lock TTL, the lock is acquired, validity time is considered to be the initial validity time minus the time elapsed
- release locks on each instance if failed to acquire lock, even on the instances it believed it was not able to lock
- try to acquire lock from multiple Redis instances sequentially, with a smaller timeout compared to lock validity time (e.g. 5~50 ms vs 10s)
- problem: safety violation upon recovery — after lock acquired, the key held on an instance can be lost when recovered from failure, making it possible for another client to acquire the lock
- solution — delayed restarted: make recovered instance unavailable for a bit more than the lock validity time, note that persistence is not helpful because
appendfsync alwayshurts
- solution — delayed restarted: make recovered instance unavailable for a bit more than the lock validity time, note that persistence is not helpful because
- variant: extend TTL when needed — use small TTL, but the lock validity is approaching a low value, the client may extend the lock by sending a Lua script to all the instances that extends the TTL of the key if the key exists and its value is still the random value the client assigned when the lock was acquired, also majority required
- ensure liveness — the maximum number of lock reacquisition attempts should be limited
- acquire lock on single instance —
sequence nodes in ZooKeeper — see ZooKeeper official docs (opens new window)
- ZooKeeper namespace — hierarchical, each node in a ZooKeeper namespace can have data associated with it as well as children, like having a file-system that allows a file to also be a directory
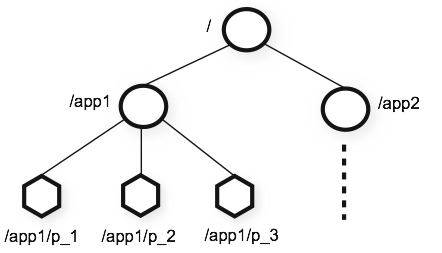
- znode
- normal node
- ephemeral node — exists as long as the session that created the znode is active, not allowed to have children
- sequence node — unique naming: when creating a znode you can also request that ZooKeeper append a monotonically increasing counter to the end of path
- ZooKeeper watches — a watch event is one-time trigger, sent to the client that set the watch, which occurs when the data for which the watch was set changes
- acquire a lock
- call
create( )with a pathname of"_locknode_/guid-lock-"and the sequence and ephemeral flags set. The guid is needed in case thecreate()result is missed - call
getChildren( )on the lock node without setting the watch flag (this is important to avoid the herd effect). - if the pathname created in step 1 has the lowest sequence number suffix, the client has the lock and the client exits the protocol.
- the client calls
exists( )with the watch flag set on the path in the lock directory with the next lowest sequence number. - if
exists( )returns null, go to step 2. Otherwise, wait for a notification for the pathname from the previous step before going to step 2.
- call
- unlock — the client delete the node it created
- advantages
- avoid herd effect — the removal of a node will only cause one client to wake up
- no polling or timeouts — ephemeral nodes deleted when session is not active, session expiration is managed by the ZooKeeper cluster
- monitor friendly — it is easy to see the amount of lock contention, break locks, debug locking problems, etc.
- ZooKeeper namespace — hierarchical, each node in a ZooKeeper namespace can have data associated with it as well as children, like having a file-system that allows a file to also be a directory
# Clustering
Load Balance
- round robin
- example — DNS, LVS, Nginx, ZooKeeper
- variant — weighted round robin
- weights — according to server metrics, such as performance
- distribution — according to algorithms, such as Monte-Carlo, GCD
- least connections
- variant — weighted least connections
- random
- variant — the choice-of-2 算法,随机选取的两个节点进行打分,选择更优的节点
- hash
- mod hash
- consistent hashing — tbd
- round robin
Redirect
- HTTP 302 Found — one more roundtrip
- DNS level load balance and redirect
- geological proximity
- long config deployment time
- server proxy
- normal server proxy
- network layer server proxy gateway, modifying IP
- data link layer server, modifying MAC address
- 直接路由 — 三角传输模式,通过配置源服务器的虚拟 IP 地址和负载均衡服务器的 IP 地址一致,从而不需要修改 IP 地址就可以进行转发。也正因为 IP 地址一样,所以源服务器的响应不需要转发回负载均衡服务器,可以直接转发给客户端,避免了负载均衡服务器的成为瓶颈
- example — LVS
session
- sticky session
- session replication
- session server
# Cache
cache properties
- hit rate
- space
- eviction strategy
- FIFO
- LRU
- LFU
- more on Cache replacement policies - Wikipedia (opens new window)
cache location
- hardware
- browser
- CDN
- gateway
- server local
- distributed
cache mode
- cache aside — resort to DB and update cache when cache miss; invalidate corresponding cache after DB write
- read through and write through
- read through — applications read cache, the cache itself determines when to update and where to update from
- write through — applications write to cache, cache update itself if cache hit and then write to DB synchronously; alternatively, in the same transaction to trade latency for consistency
- write behind — write to cache first, and asynchronously write to DB, possibly in batch
cache problems and solutions
- cache penetration — query for non-exist data eventually hits DB
- empty result cache with short expiration
- bloom filter, counting filter
- cache consistency
- cache breakdown — some hot data expired, then a large number of concurrent requests for the hot data hit DB
- lock or queues — lock on the key or use queues to ensure single thread update on one key, so latter concurrent queries will read newly updated value in cache instead of reach DB
- cache avalanche — lots of cached data expire at the same time or the cache service is down
- high availability like clustering
- properly set expiration so not simultaneous
- preload data to cache after start/restart
- 缓存 “无底洞” 现象 — 添加了大量缓存节点,但是性能不但没有好转反而下降的现象
- 原因 — 随着缓存节点数目的增加,键值分布到更多的节点上,导致客户端一次批量操作会涉及多次网络操作,这意味着批量操作的耗时会随着节点数目的增加而不断增大。此外,网络连接数变多,对节点的性能也有一定影响
- 方案 — 减少网络通信次数:优化数据分布,优化 batch,使用长连接 / 连接池,NIO 等
- cache penetration — query for non-exist data eventually hits DB
further optimization — 客户端缓存,batch,压缩,热点分桶,限流,异步化,微服务拆分,针对大流量 key 单独部署,etc.
# Rate Limit
rate limit concepts
- protection goal — application instance resources (CPU, memory), external resources like IO and backing services
- limit target
- request rate per user (session, IP address) or tenant (sub domain)
- concurrently processed requests
- request specific costs (access to dependent services, request size in MB)
- rate — fixed rate or dynamic rate
- limiting
- shed load — reject: limit the number of allowed concurrent calls
- rate throttling — delay or queue
- intercept place for Spring — general rule: apply rate limitation as early as possible in the request processing chain to avoid unnecessary consumption of resources
- servlet container filter, e.g. Tomcat valve (opens new window)
- servlet filter
org.springframework.web.servlet.HandlerInterceptor- method level — perform rate limiting directly in the method that requires protected resources
rate limit algorithms
- fixed window — periodically resetting counter, counter increment value can vary, can be implemented by key with expiration in Redis
- sliding window log — maintain a list and compare the timestamp of the head and the tail, append multiple times for time-consuming requests
- token bucket — keep a token count and a timestamp, upon a new request, refill the tokens based on elapsed time, and then take tokens and update timestamp; number of tokens taken can vary, and reject if not enough token
- semaphore — concurrent rate limit
possible HTTP response for rejected requests
- 429 Too many requests
- 503 Service not available
- header
RetryAfter: <delay-seconds|http-date>
Java libraries
- Jetty QoS Filter (opens new window) — semaphore, only for prioritization, only one semaphore for all requests
- Jetty DoS Filter (opens new window) — sliding window
- Bucket4J (opens new window) — token bucket
- Resilience4J rate limiter (opens new window) — fixed window
- Guava RateLimiter (opens new window)
- Spring Cloud Zuul RateLimit (opens new window)